DSGVO-konforme KI-Systeme mit deutsch-deid entwickeln
1. Einleitung: Die DSGVO-Herausforderung bei KI
Künstliche Intelligenz verändert viele Branchen sehr schnell. Dazu zählen Bildung, HR und Kundensupport. Unternehmen nutzen heute große Sprachmodelle in vielen Abläufen. So gewinnen sie mehr Automatisierung und Effizienz. Gleichzeitig brauchen DSGVO-konforme KI-Systeme klare Regeln für den Datenschutz.
Viele KI-Lösungen nutzen externe APIs. Diese liegen oft außerhalb der EU. Deshalb steigt das DSGVO-Risiko, sobald personenbezogene Daten ins Spiel kommen. Unternehmen senden dabei Nutzereingaben an externe Dienste oder Dritte. Dazu gehören etwa Antworten von Lernenden oder Informationen von Kunden. So kann es zu einer unbeabsichtigten Offenlegung kommen.
Daher stehen viele Organisationen vor einer schwierigen Wahl. Sie verzichten auf den Einsatz von KI bei sensiblen Daten. Oder sie akzeptieren mögliche Compliance-Risiken. Es gibt jedoch noch einen dritten Weg. Unternehmen können KI nutzen, ohne persönliche Daten offenzulegen. Genau hier kommen Datenanonymisierung und Tools wie deutsch-deid ins Spiel.
2. Warum klassische Ansätze nicht ausreichen
Auf den ersten Blick wirkt DSGVO-Compliance bei KI einfach. Systeme sollen personenbezogene Daten erkennen und maskieren. Danach senden sie den Text an ein Sprachmodell. In der Praxis ist das jedoch deutlich schwerer.
Viele Systeme nutzen Regex-Muster als erste Schutzschicht. Das funktioniert gut bei strukturierten Daten. Dazu gehören E-Mails, Telefonnummern und klar formatierte Kennungen. Allerdings ist echte Nutzereingabe oft unstrukturiert. Außerdem hängt sie stark vom Kontext ab. Namen, Adressen oder IDs erscheinen deshalb in vielen Formen. Regex allein erkennt diese Formen nicht zuverlässig.
Zudem verstehen regelbasierte Ansätze keine Bedeutung. Deshalb übersehen sie indirekte Hinweise. Oder sie markieren harmlose Inhalte fälschlich als sensibel. Hinzu kommen länderspezifische Kennungen. In Deutschland zählen dazu etwa SVNR und Steuer-ID. Generische Muster decken solche Daten oft nicht vollständig ab. Daher bleibt Regex ein sinnvoller erster Schritt. Für robuste DSGVO-Compliance im großen Maßstab reicht Regex allein aber nicht aus.
3. Was ist deutsch-deid?
deutsch-deid ist eine Open-Source-Bibliothek. Sie löst ein sehr klares Problem. Sie ermöglicht datenschutzfreundliche KI-Nutzung für deutschsprachige Daten.
Die Bibliothek nutzt keine rein generischen Anonymisierungstools. Stattdessen fokussiert sie sich auf deutsche Muster bei personenbezogenen Daten. So arbeitet sie oft präziser. Sie erkennt und anonymisiert sensible Angaben wie Namen, Adressen und besonders deutsche Kennungen. Dazu gehören die SVNR und die Steuer-ID.
deutsch-deid ist außerdem für moderne KI-Pipelines nützlich. Entwickler können Texte zuerst vorbereiten. Erst danach senden sie Inhalte an externe LLM-APIs. So verlassen keine rohen personenbezogenen Daten das System.
Einfach gesagt: deutsch-deid bildet eine Datenschutzschicht zwischen Ihren Daten und dem KI-Modell.
4. Wie deutsch-deid DSGVO-freundliche KI ermöglicht
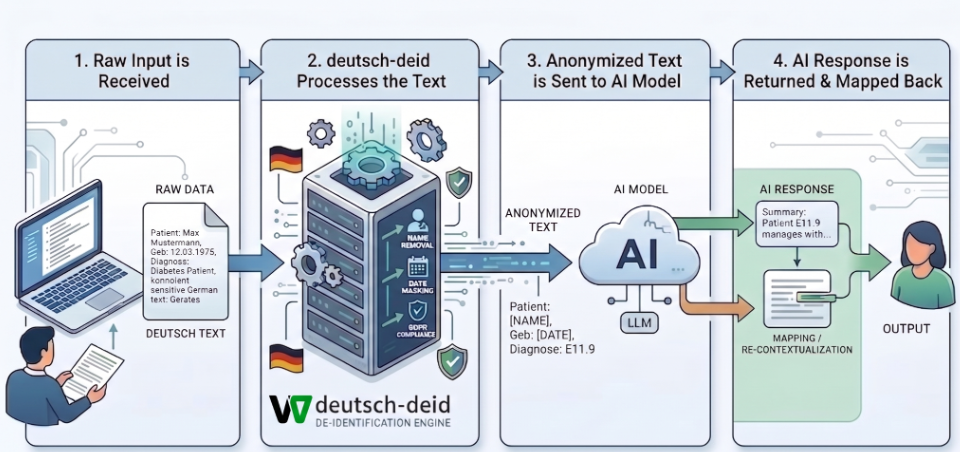
Die Grundidee von deutsch-deid ist einfach. Zuerst anonymisieren Teams die Daten. Danach nutzen sie KI.
Unternehmen senden also keine Rohdaten direkt an ein LLM. Stattdessen verarbeitet zuerst die Anonymisierungsschicht den Inhalt. So bleiben personenbezogene Informationen im System.
Ein typischer Workflow sieht folgendermaßen aus:
- Das System empfängt Rohdaten.
Zum Beispiel eine Schülerantwort, eine Kundennachricht oder Formulardaten. - deutsch-deid verarbeitet den Text.
Das Tool erkennt und ersetzt sensible Inhalte. Dazu zählen Namen, Adressen, SVNR und Steuer-ID. - Das System sendet den anonymisierten Text an das KI-Modell.
Externe APIs erhalten also ausschließlich bereinigte und nicht sensible Daten. - Die KI antwortet.
Falls nötig, ordnet das System die Antwort später wieder zu.
Diese Architektur senkt DSGVO-Risiken deutlich. Denn keine rohen personenbezogenen Daten verlassen die Systemgrenze. Gleichzeitig können Organisationen leistungsstarke LLMs weiter nutzen. Außerdem behalten sie die volle Kontrolle über sensible Informationen.
5. Deutsche Kennungen: Warum sie wichtig sind
Ein zentraler Vorteil von deutsch-deid liegt im Fokus auf deutsche sensible Datentypen. Viele generische Anonymisierungstools übersehen genau diese Daten.
Besonders wichtig sind die SVNR und die Steuer-ID. Diese Kennungen sind hochsensibel. Außerdem regelt die DSGVO ihren Umgang streng. Es handelt sich nicht um zufällige Zeichenfolgen. Diese Kennungen verweisen rechtlich eindeutig auf eine Person im deutschen Verwaltungssystem. Wenn externe KI-Dienste solche Daten sehen, entstehen ernste Datenschutz- und Compliance-Risiken.
Genau hier liegt die Herausforderung. Viele generische PII-Systeme kennen diese Formate nicht gut genug. Deshalb übersehen sie solche Angaben komplett. Oder sie erkennen Varianten im echten Text nicht konsistent. deutsch-deid schließt diese Lücke. Das Tool nutzt eine deutsche Erkennungslogik. So identifiziert und anonymisiert es diese Felder verlässlich. Daher ist es besonders wertvoll für Anwendungen im deutschsprachigen Raum. Dort sind die Anforderungen oft strenger und die Daten besonders sensibel.
6. Anwendungsfälle, besonders für EdTech
Der Nutzen von deutsch-deid zeigt sich besonders gut in realen Anwendungen. Das gilt vor allem dort, wo Systeme sensible Texte in großem Umfang verarbeiten.
Ein sehr wichtiger Bereich ist EdTech. Plattformen analysieren dort Antworten von Lernenden. Sie erzeugen Feedback. Oder sie bieten KI-gestütztes Tutoring an. Dabei verarbeiten sie oft persönliche oder teilweise persönliche Daten. Wenn Teams Rohdaten an externe LLM-APIs senden, entsteht daher schnell ein DSGVO-Problem.
Mit einer Anonymisierungsschicht wie deutsch-deid können Bildungsunternehmen sicherer arbeiten. Sie können Antworten von Lernenden analysieren, ohne Identitäten offenzulegen. Sie können KI-Feedback erzeugen und gleichzeitig persönliche Daten schützen. Außerdem können sie automatisierte Bewertungssysteme compliant skalieren.
Dasselbe Prinzip funktioniert auch in anderen Bereichen:
- HR und Recruiting bei Lebensläufen und Kandidatenprofilen
- Kundensupport bei Nachrichten und Tickets
- Gesundheitswesen bei administrativen, nicht klinischen Texten
In all diesen Fällen bleibt der Kernnutzen gleich. Teams können LLMs nutzen, ohne rohe personenbezogene Daten an externe Systeme zu senden.
7. Sichere KI braucht auch eine starke Lernumgebung
Gerade im EdTech-Bereich reicht Datenschutz allein nicht aus. Auch die Lernumgebung muss klar, strukturiert und alltagstauglich sein. Genau hier passt TueEs gut ins Bild. Die Plattform unterstützt Sprach- und Integrationskurse mit strukturierten Lernpfaden, virtuellem Unterricht und transparenter Lernfortschrittsbegleitung. Außerdem setzt TueEs KI dort ein, wo sie Lernprozesse sinnvoll unterstützt, ohne die Lehrkraft zu ersetzen.
Wer also DSGVO-konforme KI nicht nur technisch, sondern auch didaktisch sinnvoll einsetzen möchte, kann mit TueEs digitale Kursarbeit, Lernbegleitung und KI-gestützte Unterstützung in einer Plattform verbinden.

8. Grenzen und wichtige Punkte
deutsch-deid verbessert den Datenschutz in KI-Workflows deutlich. Trotzdem löst das Tool nicht jedes Problem automatisch.
Wie bei allen Anonymisierungssystemen hängt viel von der Eingabe ab. Texte aus der Praxis sind oft unklar, unruhig oder mehrdeutig. Außerdem enthalten sie manchmal indirekte Hinweise auf Personen. Solche Hinweise erkennt ein System schwerer. Deshalb können Randfälle auftreten. Das System kann einzelne Angaben übersehen. Oder es markiert Inhalte zu streng.
Teams sollten deutsch-deid deshalb als Schutzschicht sehen. Sie sollten es nicht als vollständige Compliance-Garantie verstehen. In sensiblen Produktivumgebungen kombinieren viele Organisationen das Tool zusätzlich mit Prüfungen oder domänenspezifischen Regeln. Trotzdem bleibt der Hauptvorteil groß. Das Tool senkt das Risiko einer Offenlegung roher personenbezogener Daten deutlich. Dadurch wird DSGVO-freundliche KI-Nutzung sehr viel praktikabler.
9. Fazit
Die Nutzung von KI wächst schnell. Deshalb wird Datenschutz zu einer der wichtigsten Bedingungen für den realen Einsatz. Das gilt besonders unter der DSGVO.
Die zentrale Frage lautet heute nicht mehr, ob KI nützlich ist. Die eigentliche Frage lautet: Wie nutzen Teams KI, ohne sensible personenbezogene Daten offenzulegen? deutsch-deid bietet dafür einen praktischen Ansatz. Das Tool fügt eine Anonymisierungsschicht für deutschsprachige Daten ein. Es erkennt und entfernt sensible Informationen. Dazu zählen besonders deutsche Kennungen wie SVNR und Steuer-ID. So können Organisationen LLMs sicherer in ihre Abläufe integrieren.
Die wichtigste Erkenntnis bleibt einfach: Zuerst anonymisieren, dann KI nutzen. So profitieren Unternehmen von moderner KI. Gleichzeitig senken sie Risiken. Außerdem behalten sie die Kontrolle über persönliche Daten. Für Teams in Europa, besonders in Bildung, HR und sensiblen Bereichen, entsteht damit ein klarer Weg nach vorn: DSGVO-konforme KI-Systeme, ohne die Privatsphäre zu gefährden.
Für weitere Einblicke in moderne EdTech-Szenarien lesen Sie unseren aktuellen Blogbeitrag: KI-gestützte Echtzeit-Bewertungssysteme
Disclaimer:
Dieser Blog dient ausschließlich zu Informations- und Aufklärungszwecken. Die Inhalte können durch andere Quellen überprüft werden. Der Autor übernimmt keine rechtliche Verantwortung für Entscheidungen, die auf Grundlage dieser Informationen getroffen werden.
Wilhelm Digital | Lernen für alle zuganglich machen!
